ParseR combines functionality from the widyr package
and the tidygraph
package to enable users to create network visualisations of the
pairwise correlations with specified terms.
We’ll play through an example using a sample of the data set included in the ParseR package.
# Generate a sample
set.seed(1)
example <- ParseR::sprinklr_export %>%
dplyr::slice_sample(n = 1000)N.B. The function dplyr::slice_sample(n = 1000)
is only used in this tutorial to speed up the analysis and workflow, a
sample of 1000 should NOT be taken during project work. If you have any
worries with the size of data or speed of analyses speak to one of the
DS team.
Calculate the pairwise correlations
Each post will be broken down into individual words, then the words whose occurrence is correlated with terms that we’re interested in will be returned.
- The correlation we’re calculating and using here is called the phi coefficient and is denoted by .
- It’s a measure of association for two binary variables.
- For a pair of words we can interpret it as how much more likely it is that both or neither of the words appear in a document than that either one appears alone.
- For more information check out either tidytextmining or wikipedia.
corrs <- ParseR::calculate_corr(
# We must specify the data set we're using
df = example,
# We must specify the text variable in our dataset
text_var = Message,
# We must specify terms we're interested in
terms = c(
"hispanic", # Can use single words
"hispanic heritage", # Can use multi-word phrases (e.g. brands, names)
"#hispanicheritagemonth"
), # Can use hashtags
# We can specify a minimum term frequency
min_freq = 25,
# We can specify correlation limits
corr_limits = c(0, 1), # E.g. We only want positive correlations
# We can specify the top_n correlations to include
n_corr = 50,
# We can specify whether to include hashtags in the text
hashtags = TRUE,
clean_text = TRUE
) # clean the text variable in placeNote that corrs is a list object:
class(corrs)## [1] "list"It contains two objects:
- “view”
- A human-readable tibble with the top correlations involving our terms of interest.
corrs %>%
purrr::pluck("view")## # A tibble: 50 × 3
## from to correlation
## <chr> <chr> <dbl>
## 1 hispanic membership 0.483
## 2 hispanic caucus 0.473
## 3 hispanic beto 0.466
## 4 hispanic flashback 0.457
## 5 hispanic refuses 0.456
## 6 hispanic bobby 0.456
## 7 hispanic lacks 0.456
## 8 hispanic orourke 0.455
## 9 hispanic_heritage month 0.449
## 10 hispanic via 0.260
## # ℹ 40 more rows- “viz”
- A
tbl_graphobject that can be used to produce a network visualisation.
corrs %>%
purrr::pluck("viz")## # A tbl_graph: 38 nodes and 50 edges
## #
## # An undirected multigraph with 1 component
## #
## # Node Data: 38 × 2 (active)
## word term_freq
## <chr> <int>
## 1 hispanic 133
## 2 membership 31
## 3 caucus 34
## 4 beto 44
## 5 flashback 28
## 6 refuses 30
## 7 bobby 30
## 8 lacks 31
## 9 orourke 38
## 10 hispanic_heritage 500
## # ℹ 28 more rows
## #
## # Edge Data: 50 × 3
## from to correlation
## <int> <int> <dbl>
## 1 1 2 0.483
## 2 1 3 0.473
## 3 1 4 0.466
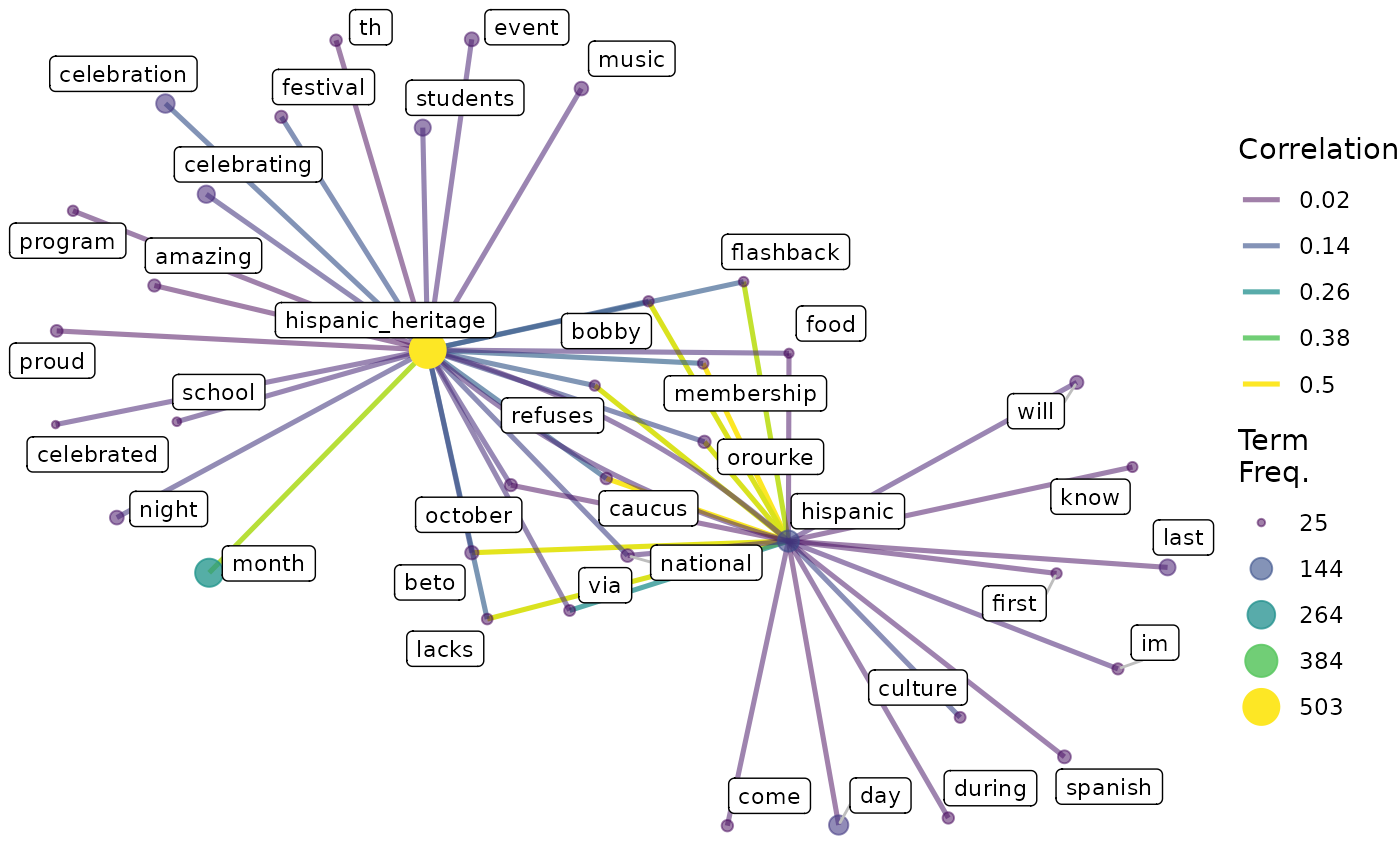
## # ℹ 47 more rowsVisualise the network
Now we can use the tbl_graph object we generated using
calculate_corr() to produce a network visualisation.