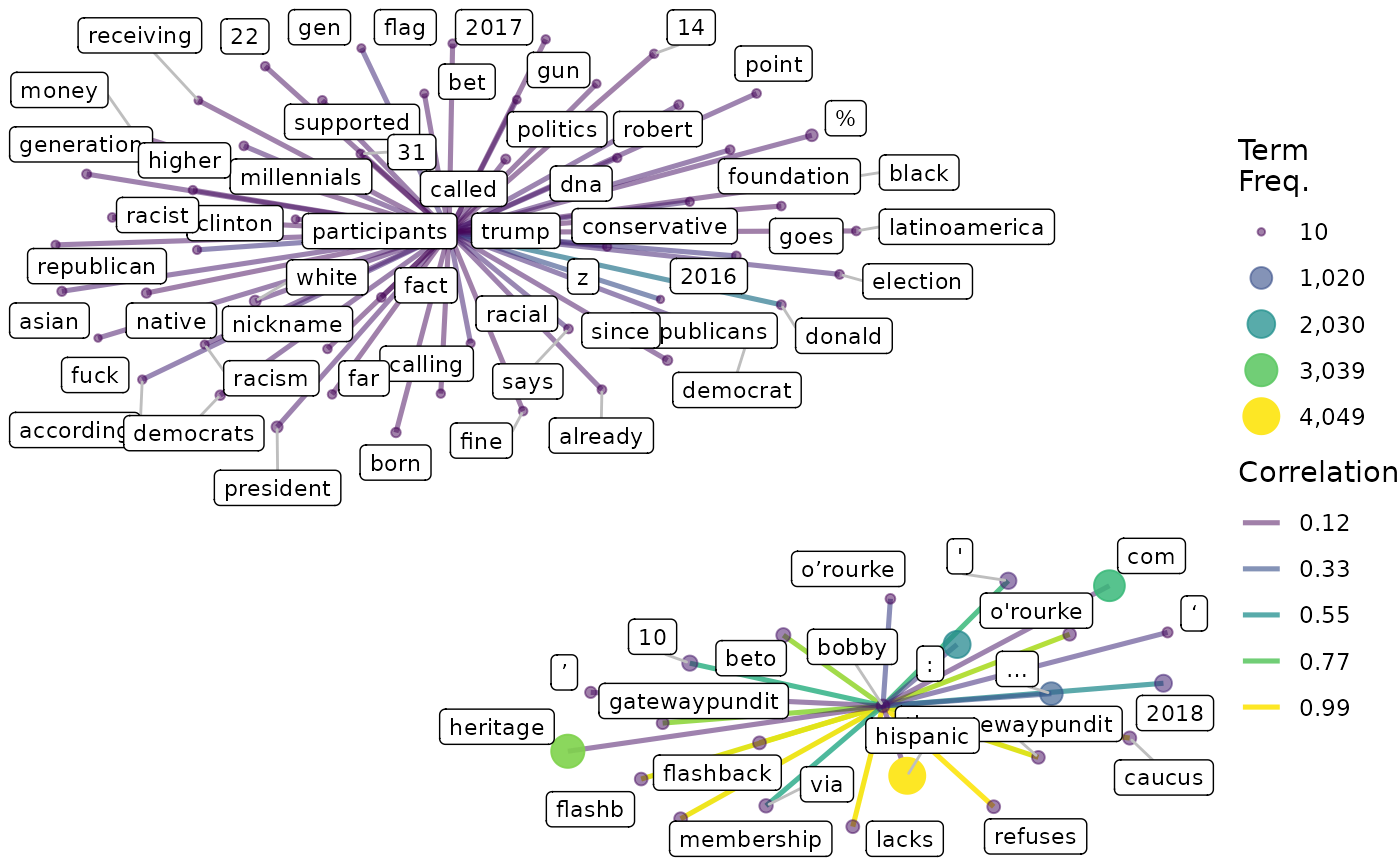
Generate pairwise correlations for a vector of terms of interest.
Source:R/calculate_corr.R
calculate_corr.RdGenerate pairwise correlations for a vector of terms of interest.
Usage
calculate_corr(
df,
text_var,
terms,
min_freq = 10,
corr_limits = c(-1, 1),
n_corr = 75,
hashtags = FALSE,
mentions = FALSE,
clean_text = FALSE
)Arguments
- df
A dataframe where each row is a separate post.
- text_var
The variable containing the text which you want to explore.
- terms
The terms of interest. You can use multi-word phrases.
- min_freq
The minimum number of times a term must be observed to be considered.
- corr_limits
Numerical lower and upper bounds for correlations.
- n_corr
The number of correlations to include (begins with the most positive within the range specified in corr_limits).
Should hashtags be included?
- mentions
Should mentions be included?
- clean_text
Should the text variable be cleaned?
Value
A list containing a summary table and a tidygraph object suitable for a network visualisation.
Examples
{spinklr_export <- ParseR::sprinklr_export
x <- calculate_corr(
df = sprinklr_export,
text_var = Message,
terms = c("bobby", "trump"),
min_freq = 10,
corr_limits = c(-1, 1),
n_corr = 75,
hashtags = TRUE,
mentions = FALSE
)
viz_corr(x$viz)
}