The Emotions Dictionary
Heath and Heath (2017) proposed a taxonomy in The Power of Moments, where a moment is defined as a short experience that is both memorable and meaningful. Moments are created through one of the following elements - Elevation, Insight, Pride, Connection.
We have created an emotional moment dictionary that assigns terms to these moments. For example, an insightful moment may be reported through learning, thinking, or change, whereas a moment of pride could be reported through the terms champion, hero, or triumph.
We look for these terms within social data to identify moments that are prominent, helping us to understand how people feel about a brand and its products. Armed with this information, we know what can ignite an emotional connection between users and the brand.
We will run through an example using the sample data from the ParseR package.
# Generate a sample
set.seed(1)
example <- ParseR::sprinklr_export %>%
dplyr::slice_sample(n = 1000)N.B. The function dplyr::slice_sample(n = 1000)
is only used in this tutorial to speed up the analysis and workflow, a
sample of 1000 should NOT be taken during project work. If you have any
worries with the size of data or speed of analyses speak to one of the
DS team.
Moment Frequencies
Each term from the dictionary is found within the data set and counted. This helps us to identify key moments and determine the way in which they are reported.
For this data set, moments of pride and connection are particularly strong. This makes sense - the posts within the data set are all centered around Hispanic Heritage Month, so we would hope to see some focus on community.
moment_frequency <- ParseR::moment_frequencies(
df = example,
text_var = "Message"
)
moment_frequency$viz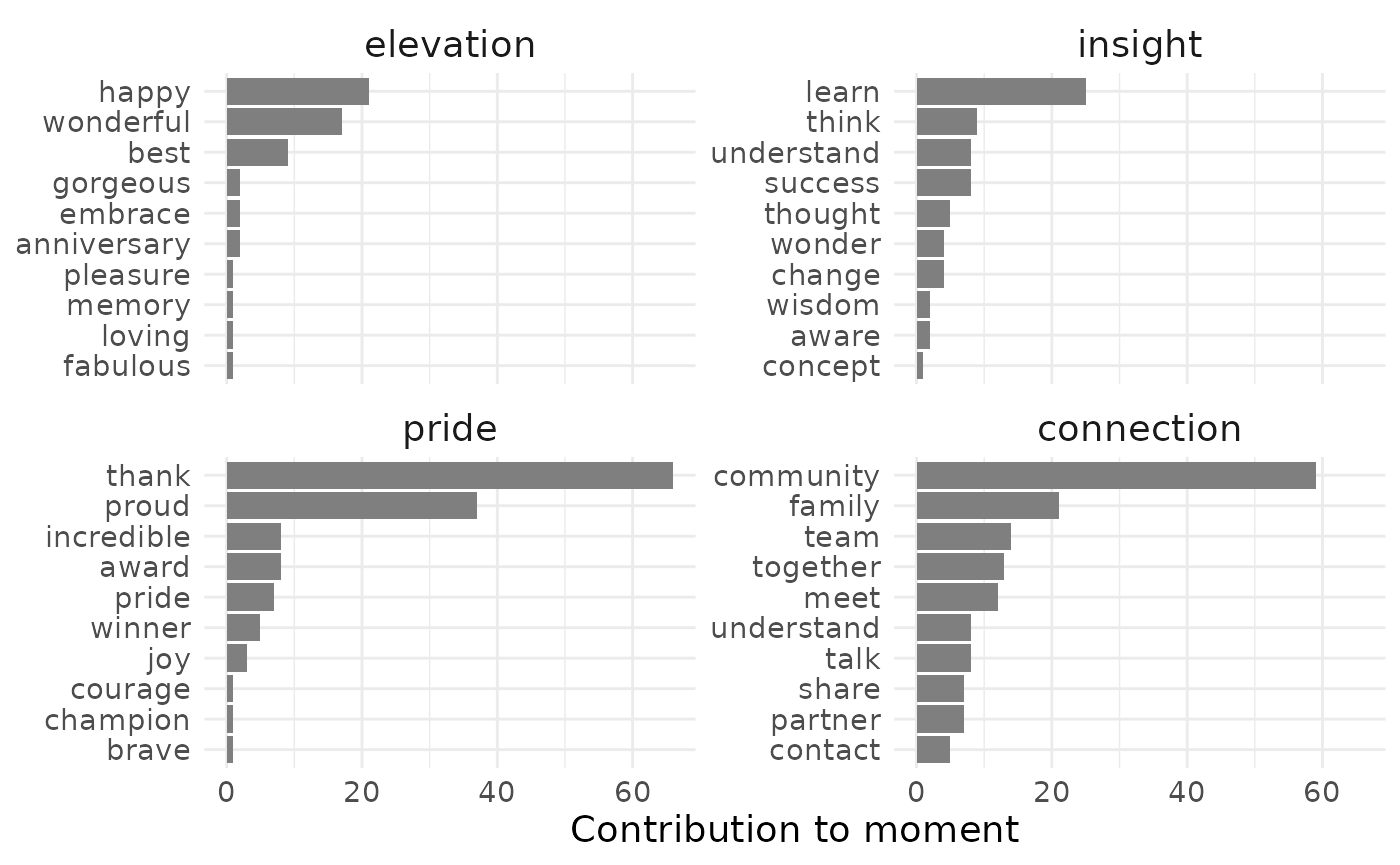
Term Correlations
Using concepts from ParseR’s calculate_corr function, we
can take a deeper dive into these stronger moments to identify the types
of situation arising. Terms that are highly correlated with a moment can
help us build a story about why certain emotions are felt.
In our example, by looking at correlated terms with community, we see cases of people sharing their experience as a Latinx community member, as well as encouraging people to join events and partake in cultural activities.
moment_correlation <- ParseR::moment_correlations(example,
text_var = "Message",
term = "community",
n_corr = 20
)
moment_correlation$viz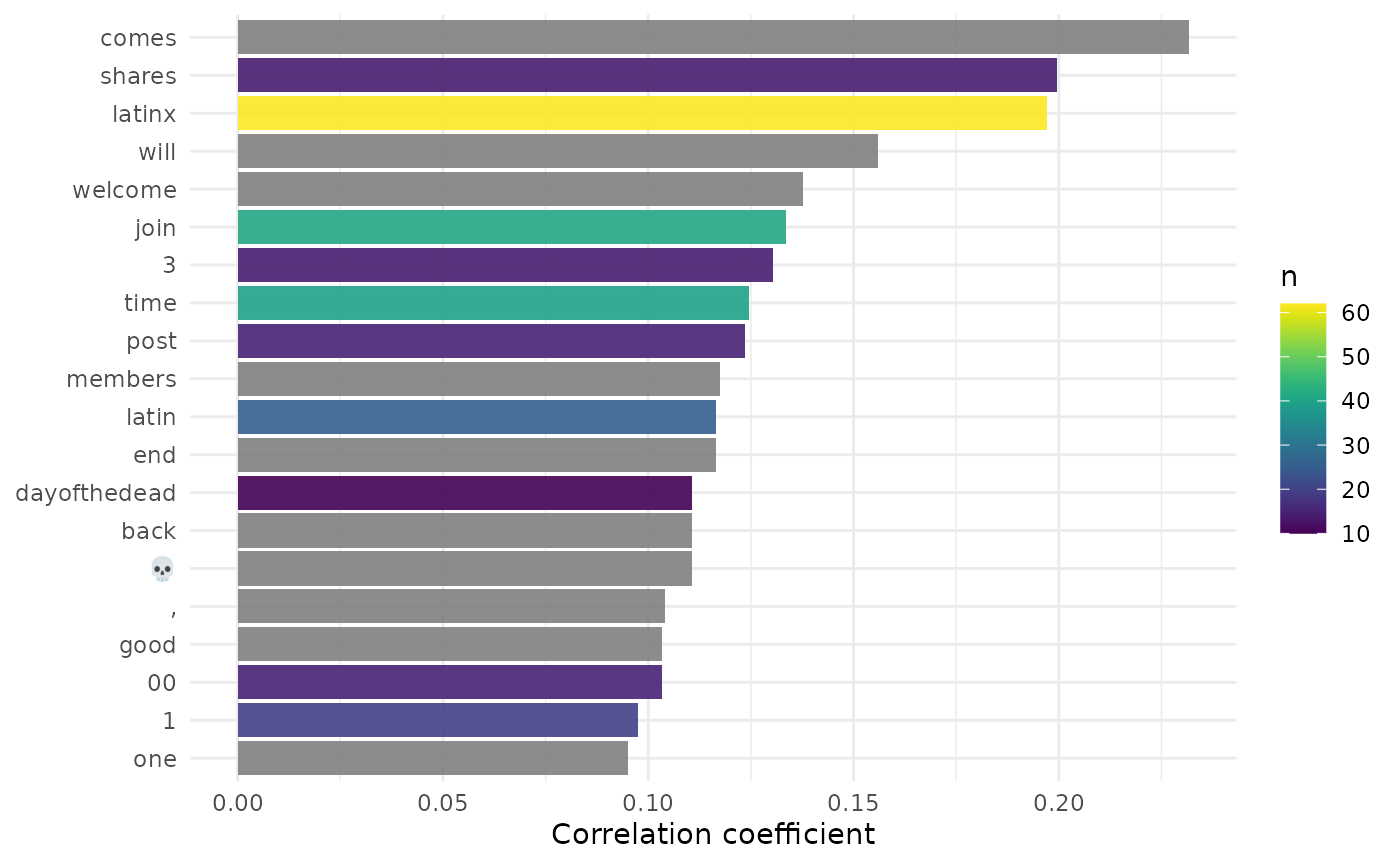
Moment Ratios
So far we have simply taken term frequencies to determine the strongest emotional moments within a given data set. This method, however, doesn’t determine the strength of moments for individual posts.
To tackle this, we calculate the moment ratio for each post. This is calculated in the following manner:
- Calculate the number of terms from the moment dictionary featuring in each post, for each of elevation, insight, connection, and pride
- Calculate the total number of words in each post
- Divide the number of moment terms by the total number of terms
For example, a post may contain 2 elevation words, and has a total of 100 words, in which case the elevation ratio would be 2 / 100 = 0.02.
ratios_df <- ParseR::calculate_ratios(example,
text_var = "Message"
)Ratios over time
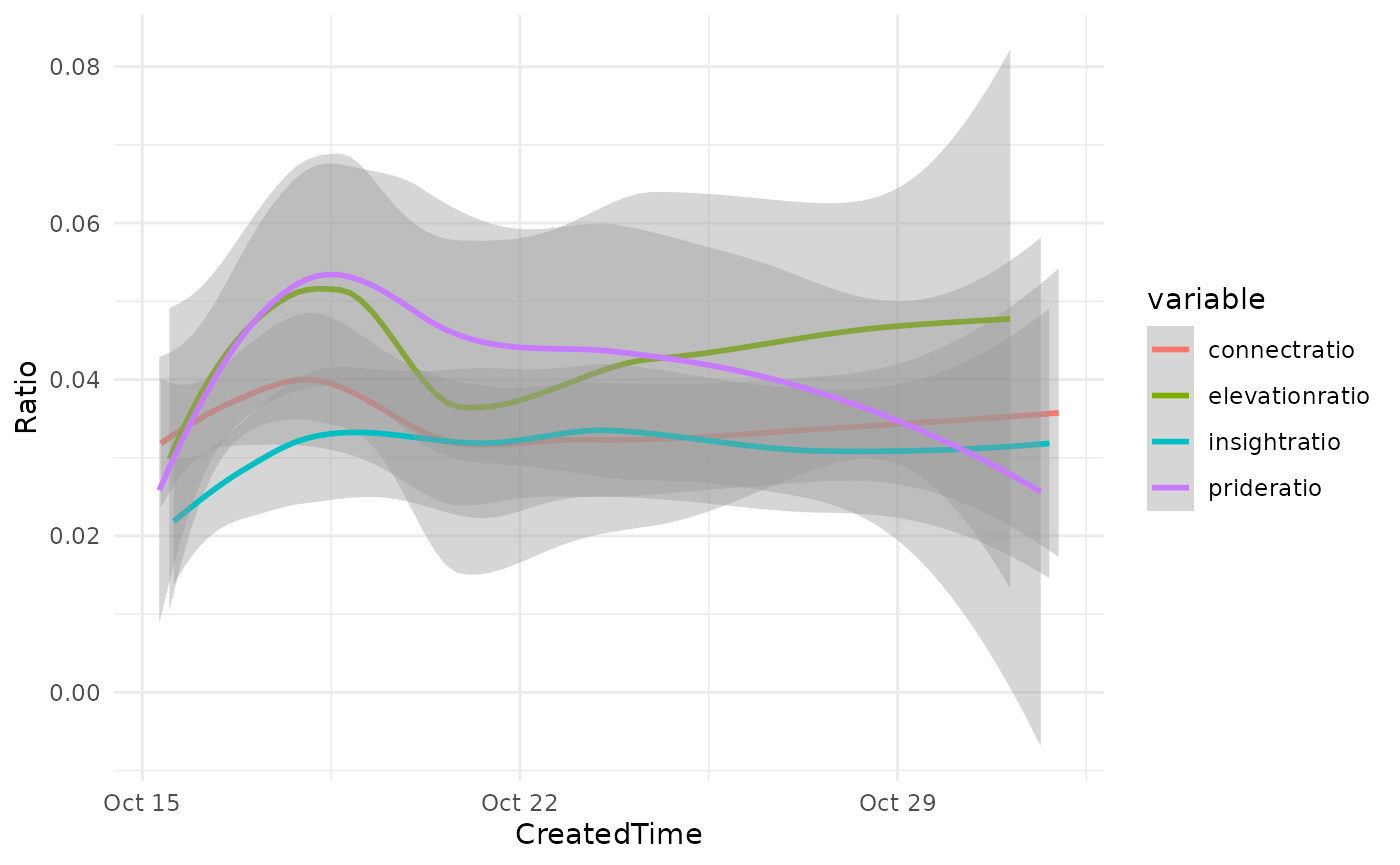
The ratios can be aggregated over time to spot peaks and pits in emotions, and determine the type of events that influence these.
In this case, emotions are higher at the start of the time period due to excitement around upcoming and completed events. This excitement teeters off as Hispanic Heritage Month comes to an end and events subside.
ParseR::ratios_over_time(ratios_df,
date_var = "CreatedTime"
)