We are often faced with the question of how conversations differ
between groups. One way of answering this question is to look at the
weighted log odds ratio (WLOs) for terms used in each group.
This value measures the strength of association between a word and a
target category in a corpus (or dataset). ParseR uses functions from the
tidylo package to calculate these. This very nice
blog by Sharon Howard outlines the utility of WLOs compared to other
methodologies to indentify word importance, such as tf-idf and this
blog post by Tyler Schnoebelen is also recommended reading.
To demonstrate how to use the calculate_wlos function,
we will use the example data included within the ParseR package.
# Example data
example <- ParseR::sprinklr_exportCalculate Weighted Log-Odds Ratios
Let’s say we want to compare how males and females talk about Hispanic Heritage Month.
# Remove rows with no gender information
example <- example %>%
dplyr::filter(SenderGender != "NA")
# Calculate WLOs
wlos <- ParseR::calculate_wlos(example,
topic_var = SenderGender,
text_var = Message,
top_n = 30
)example is a list object that contains two items:
-
view: a human-readable tibble that contains the weighted log-odds for each of the top_n = 30 terms
wlos$view## # A tibble: 60 × 4 ## SenderGender word n log_odds_weighted ## <chr> <chr> <int> <dbl> ## 1 M heritage 147 1.38 ## 2 M celebration 43 1.42 ## 3 F power 13 2.12 ## 4 M festival 13 1.23 ## 5 F put 12 2.04 ## 6 F generations 11 1.95 ## 7 F paid 10 1.86 ## 8 F panel 10 1.86 ## 9 F sources 10 1.86 ## 10 F tribute 10 1.86 ## # ℹ 50 more rows -
viz: a plot that visualises terms in the view tibble with term frequency on the x-axis, and weighted log-odds on the y-axis.
wlos$viz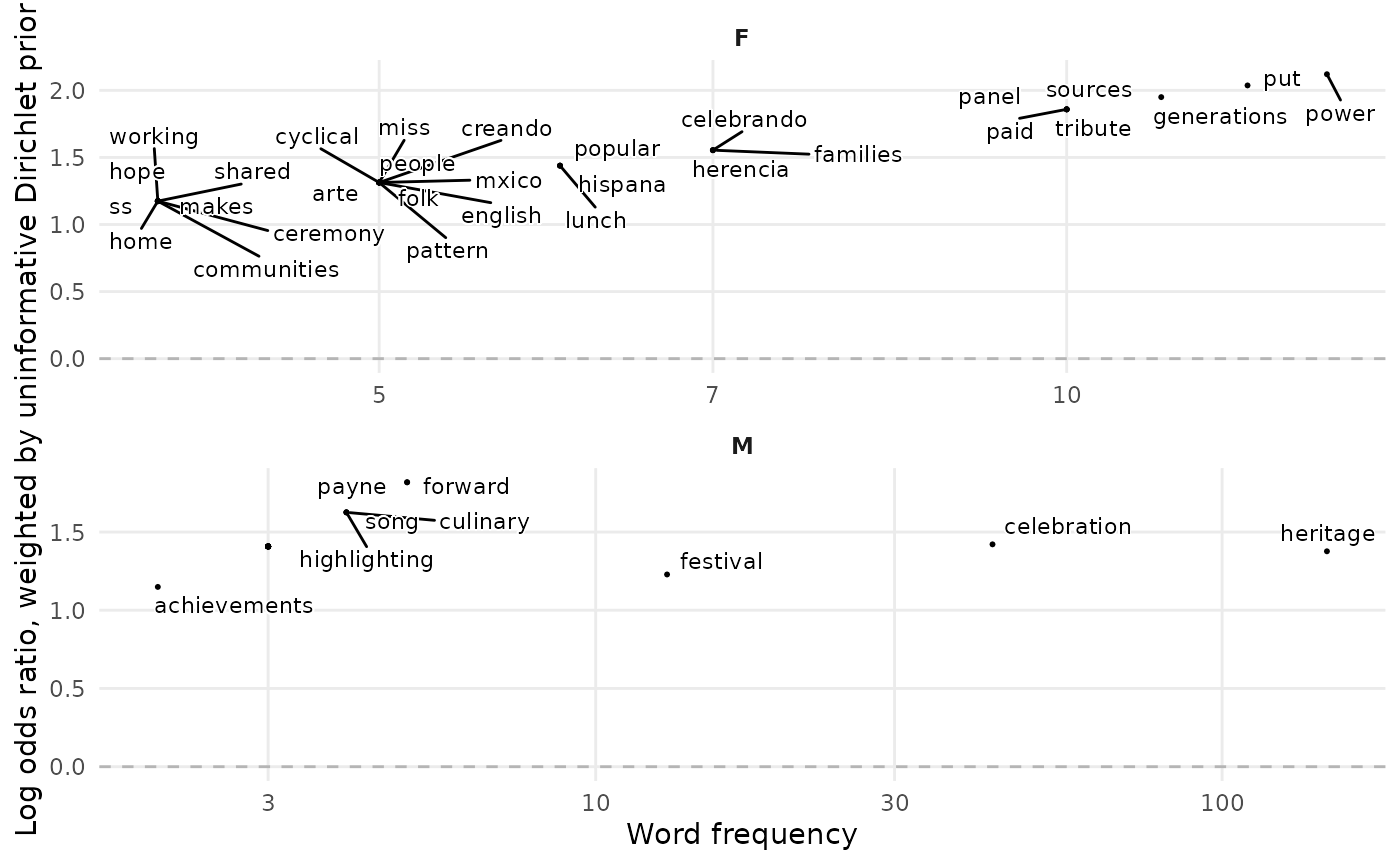
What we can learn from the plot is that men appear more likely to associate Hispanic Heritage Month with the celebratory aspects, whereas women discuss the learnings they can take from it.
Advice on interpreting Weighted Log-Odds Ratios
As mentioned at the beginning of this document, WLO is a statistical measure used to determine which words are most strongly associated with a particular category. This is calculated by comparing the frequency of each word in the target category to its frequency in all other categories within the corpus (or dataset).
The value can be interpreted as the logarithm of the ratio of the probability of observing a word in the target category to the probability of observing the same word in all other categories combined. A WLO value > 0 indicates the word or phrase is more strongly associated with the target category than with other categories, whilst a value <0 indicates the others.
In other words, it’s important to remember that the magnitude of a WLO value reflects the strength of the association, but it is not directly interpretable as a probability or frequency. Rather, it reflects the logarithmic difference between two probabilities (or odds), and should be treated as a relative measure of association.
Therefore, when reporting WLO to clients, one must refrain from using phrases such as “This term is X times as likely to appear in Category A than Category B and C”, and instead use phrases such as “This term has a stronger association with Category A than Category B and C”.